

Zenodo
bezpłatne, międzynarodowe repozytorium interdyscyplinarne utworzone dzięki inicjatywie CERN (European Organization for Nuclear Research; międzynarodowej organizacji niekomercyjnej zrzeszającej ponad 20 państw członkowskich i ponad 10 obserwujących; największego na świecie centrum badań fizyki cząstek elementarnych) i OpenAIRE (organizacji niekomercyjnej, której misją jest promowanie otwartej nauki; zarządzającej europejską e-infrastrukturą agregującą repozytoria i wspierającą deponowanie wyników badań naukowych; kluczowego podmiotu zarządzającego European Open Science Cloud). Repozytorium to jest przeznaczone dla tzw. małych danych – limit wielkości zestawu danych wynosi 50 GB (można zdeponować maksymalnie 100 plików). Każda wersja zbioru danych zdeponowanych w tym repozytorium otrzymuje unikalny numer DOI. Zenodo jest zarejestrowane w re3data.org.
Adres strony internetowej Zenodo – https://zenodo.org/
Instrukcja w wersji do pobrania
-
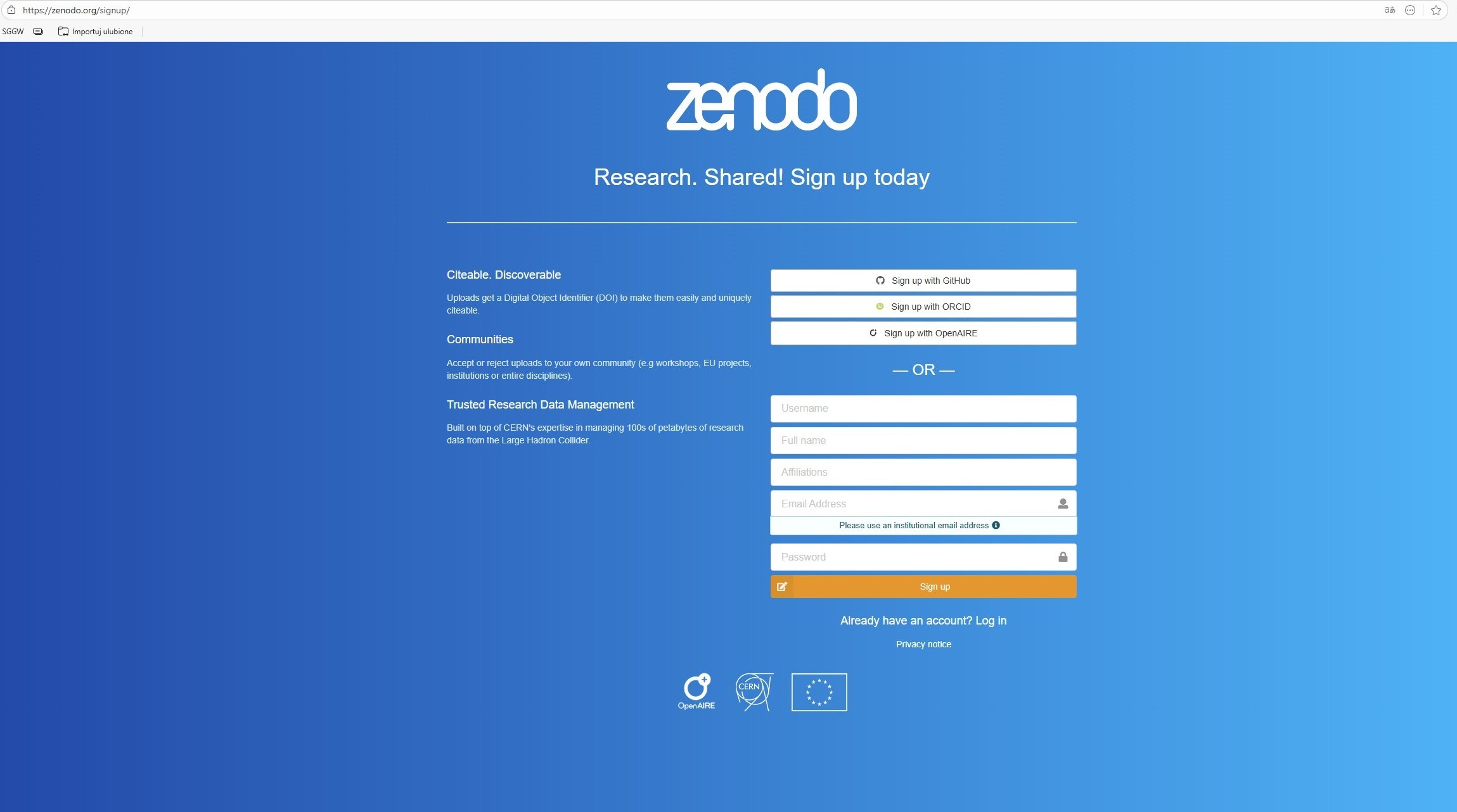
Zakładanie konta i logowanie
-
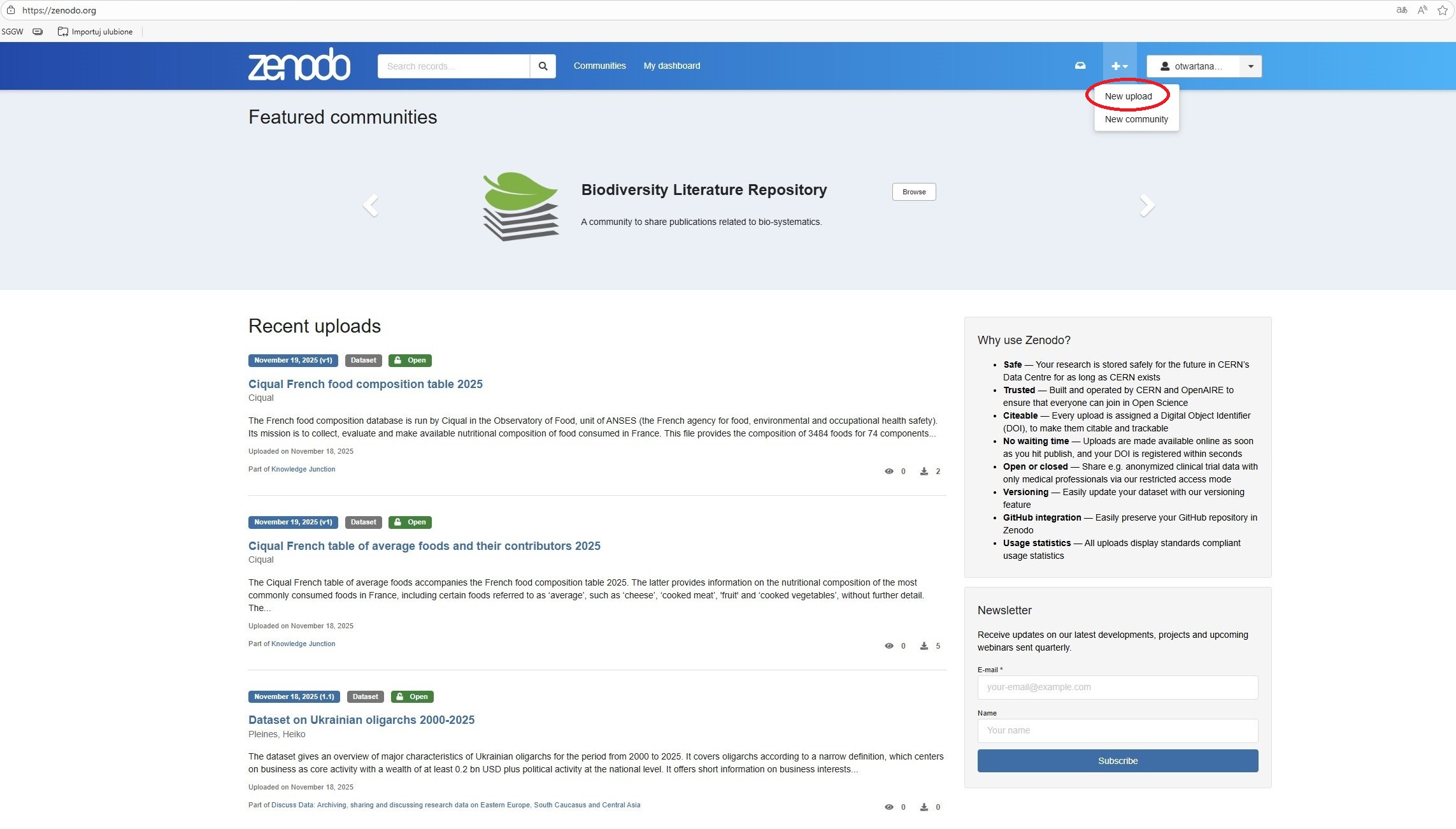
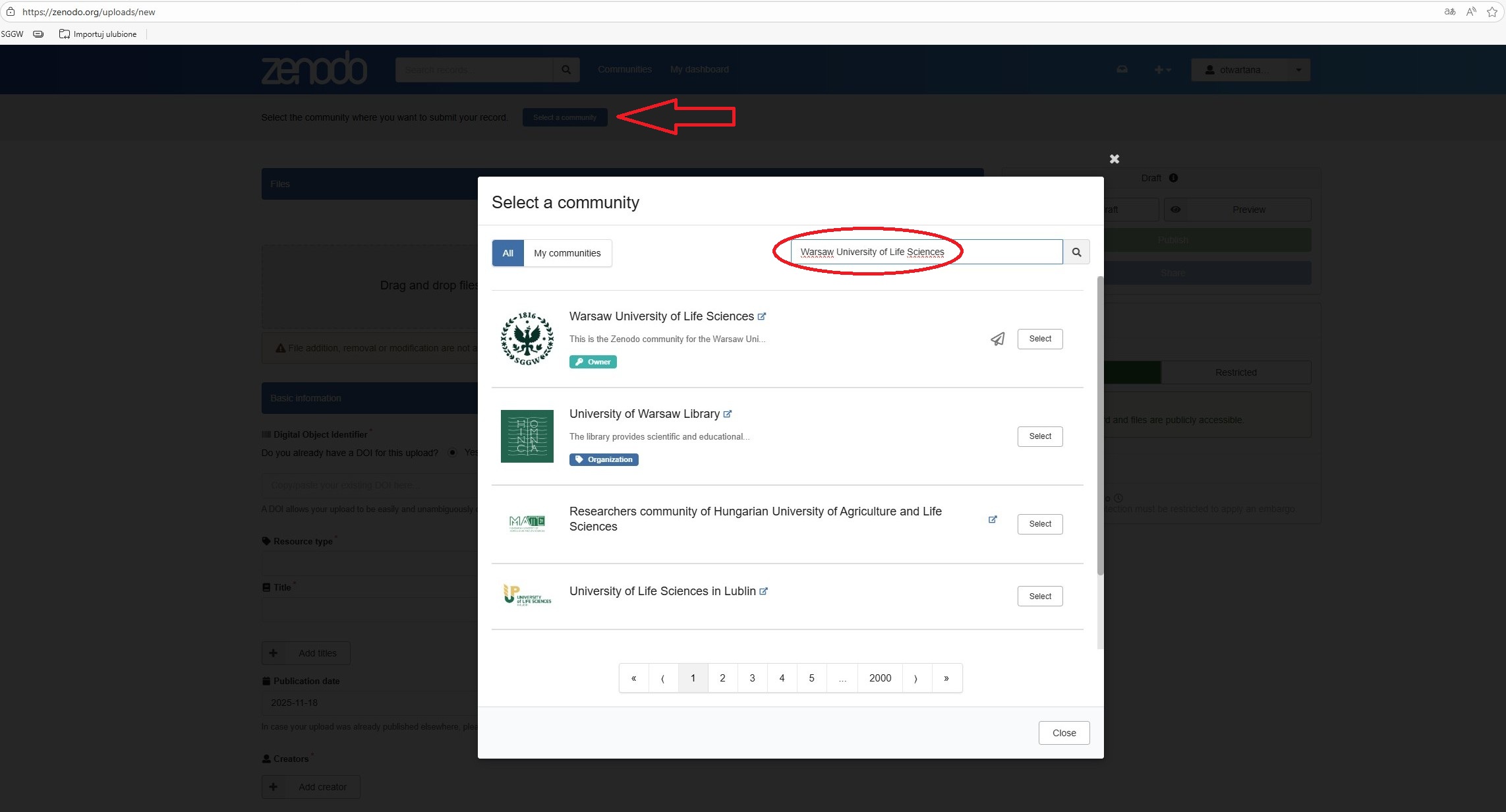
Wybór społeczności
-
Przygotowanie plików
-
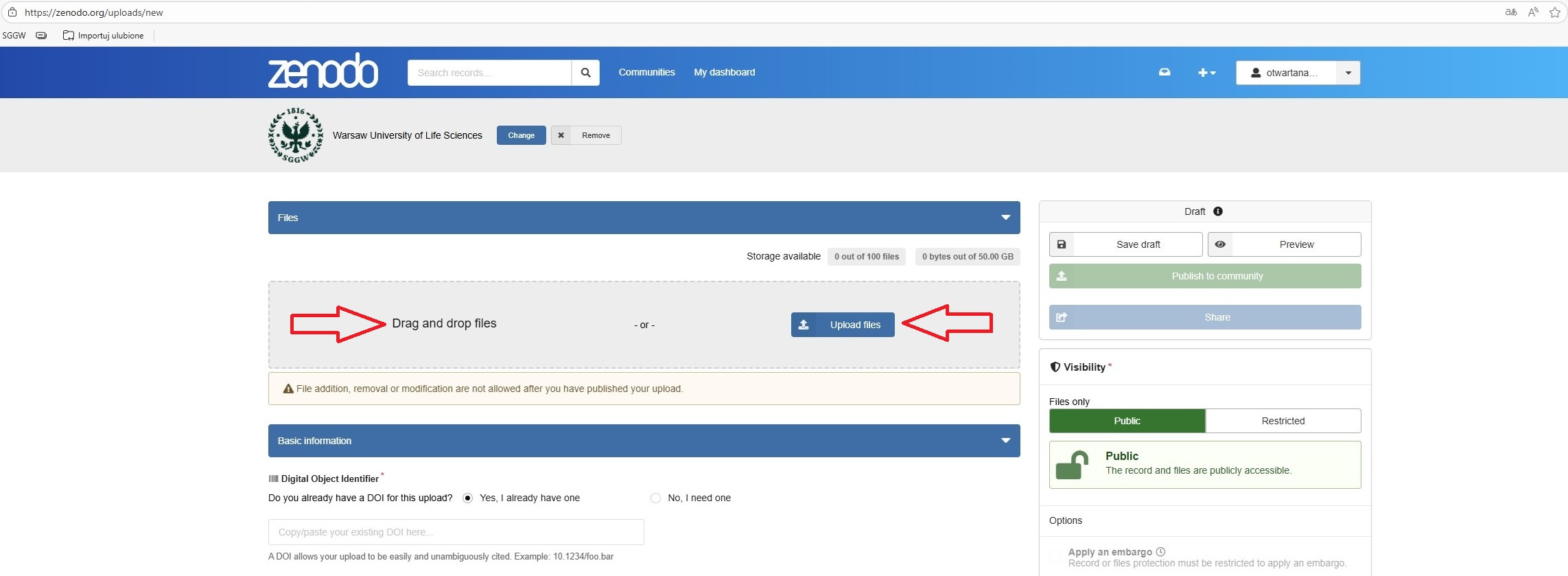
Deponowanie plików z danymi
-
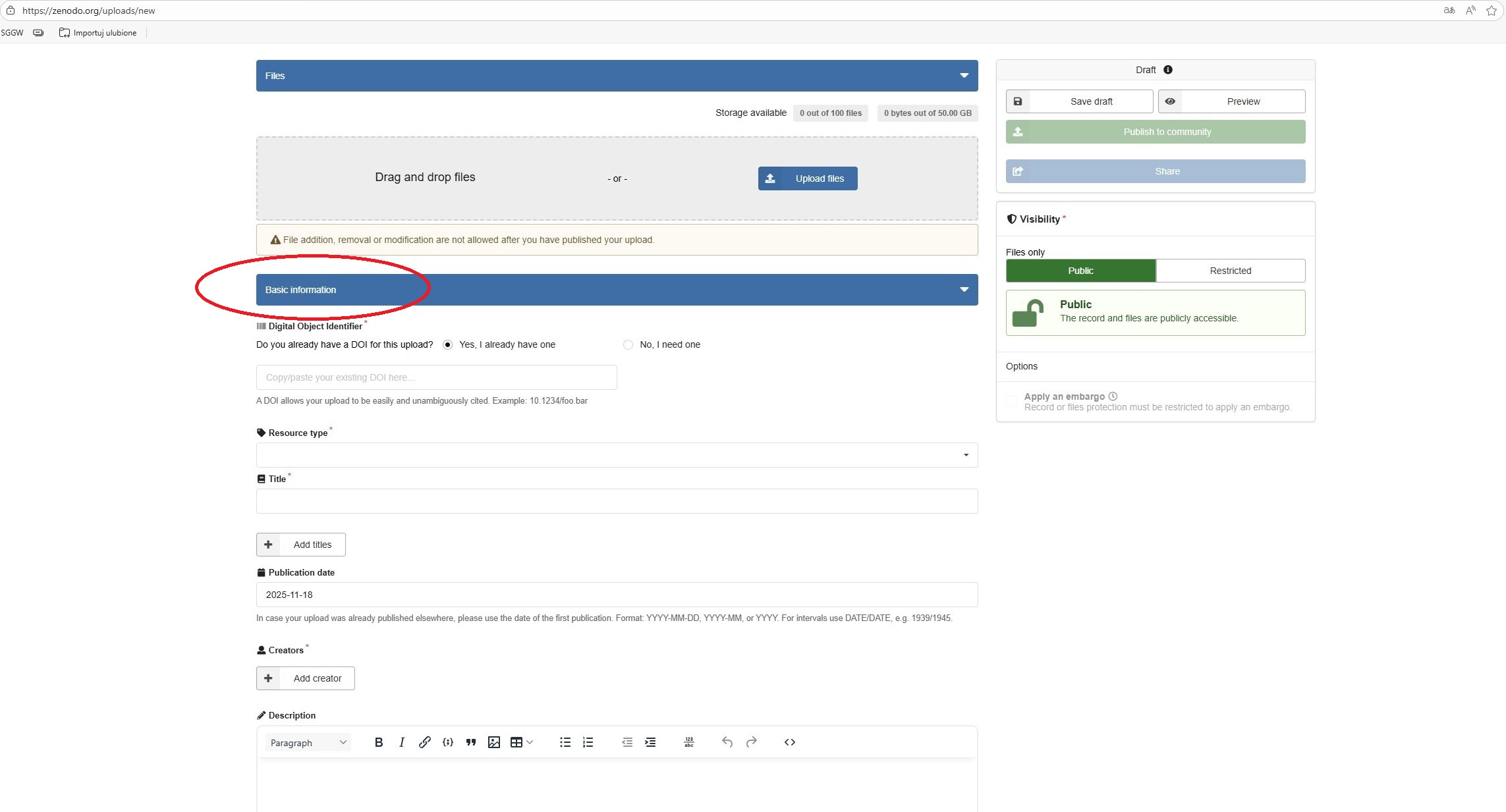
Wprowadzanie metadanych
-
Digital Object Identifier

-
Resource type
-
Title
-
Publication date
-
Creators
-
Description
-
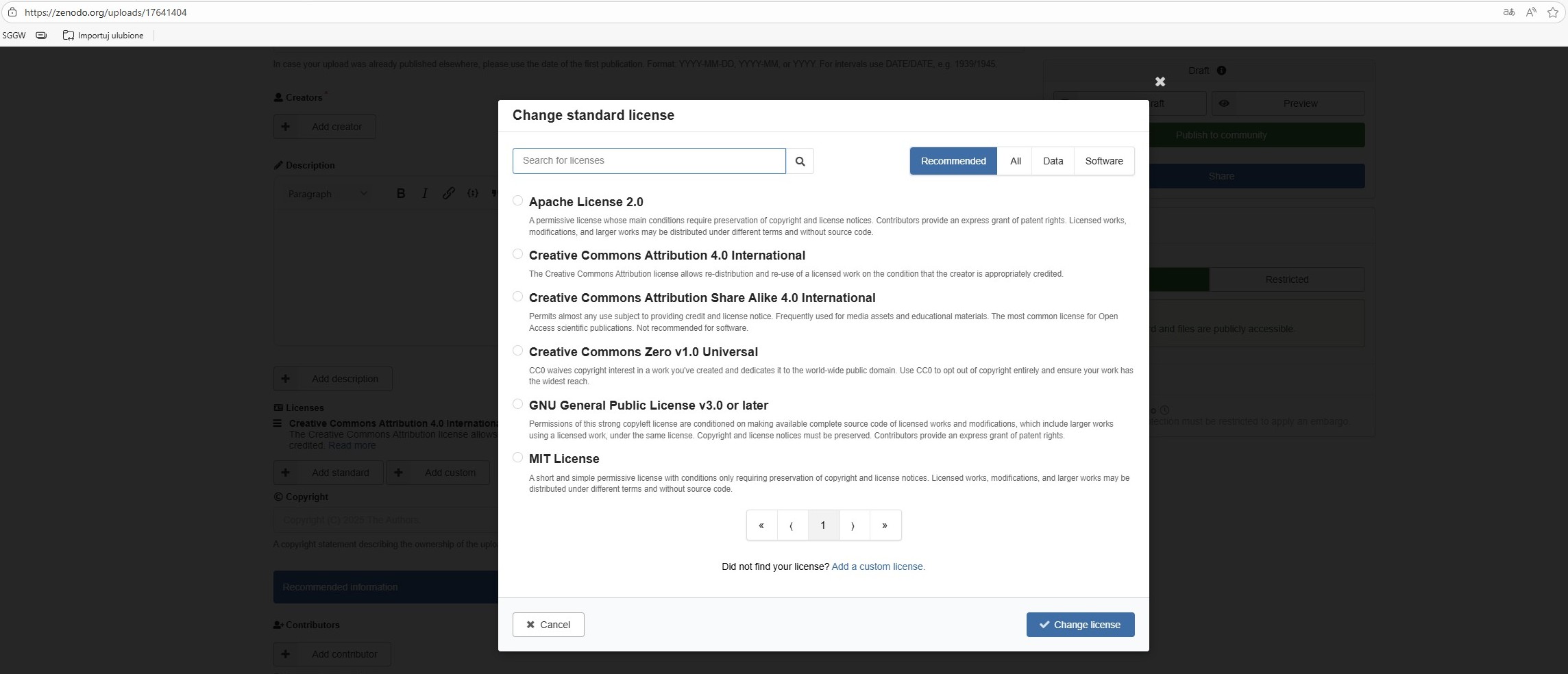
Licenses

-
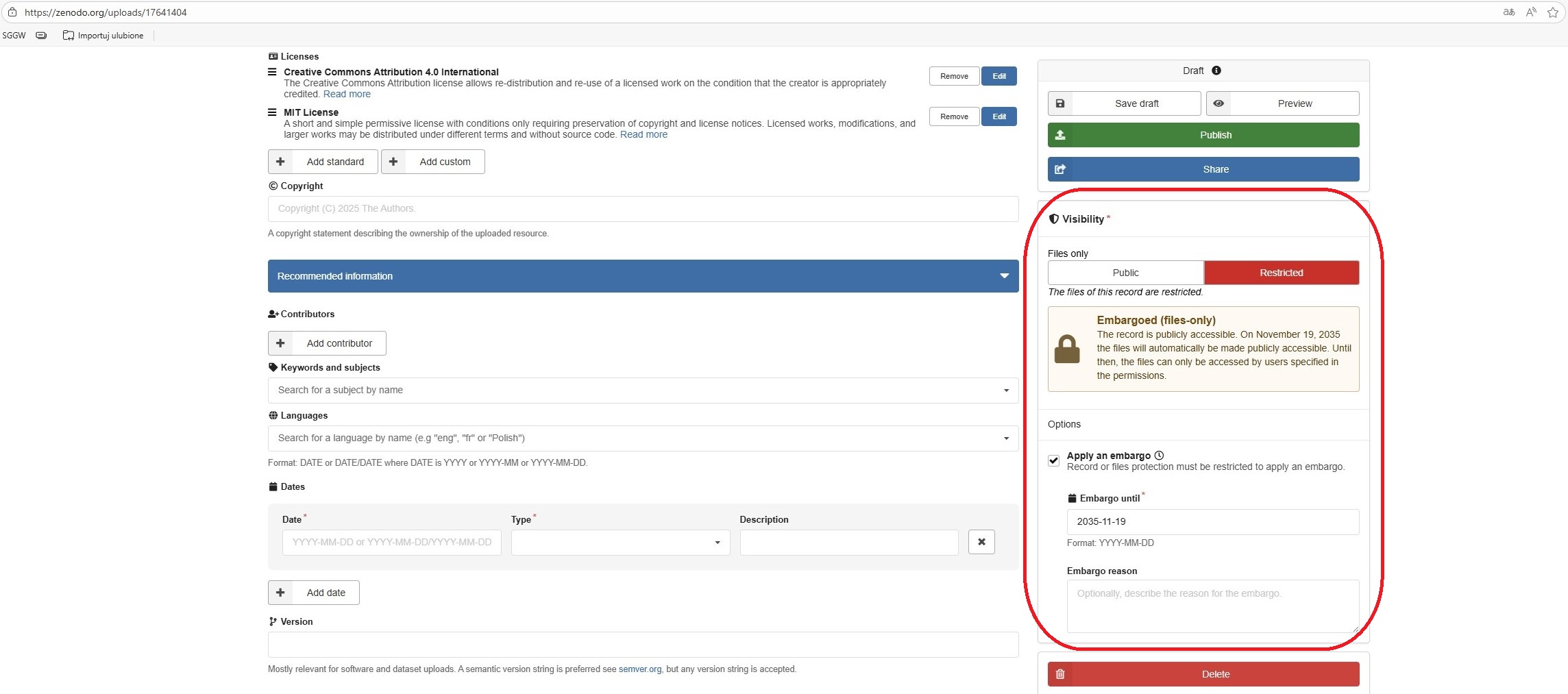
Embargo
-
Contributors
-
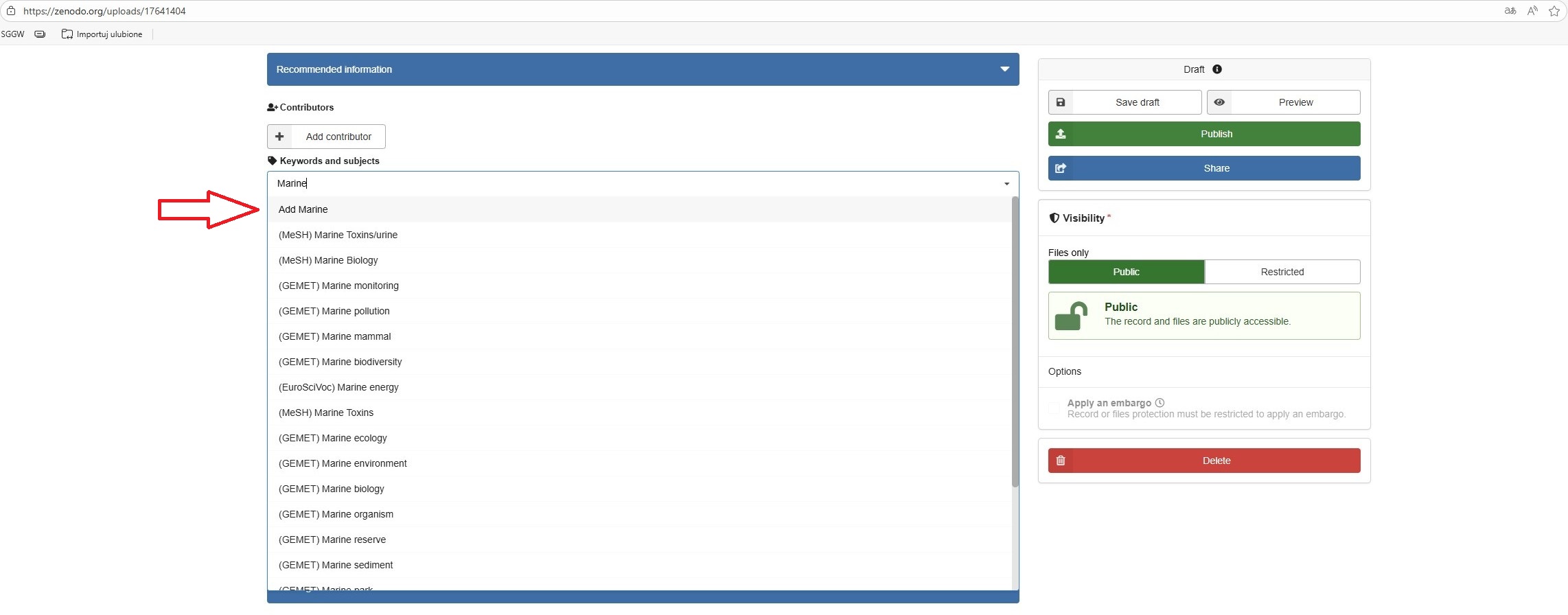
Keywords and subjects
-
Languages
-
Dates
-
Version
-
Publisher
-
Funding
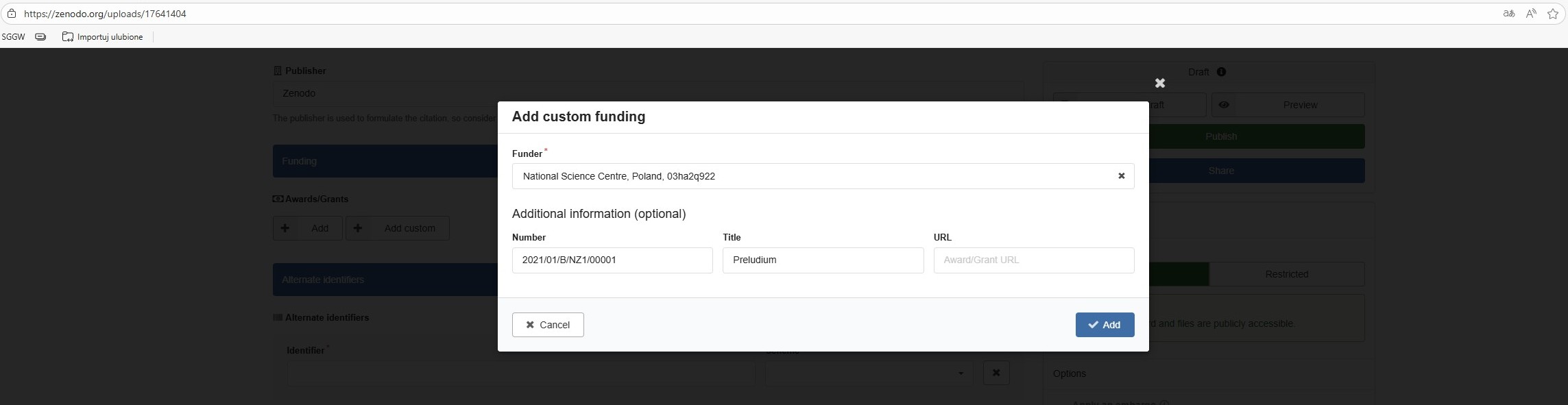
-
Alternate identifiers
-
Related works
-
References
-
Pozostałe pola