
![]()
RepOD (Repozytorium Otwartych Danych)
bezpłatne, polskie repozytorium interdyscyplinarne, które powstało w ramach projektu Dziedzinowe Repozytoria Otwartych Danych Badawczych realizowanego przez zespoły projektowe w ICM UW, ISS UW, IFiS PAN w Warszawie i UAM w Poznaniu. Repozytorium to jest przeznaczone dla tzw. małych danych – limit wielkości pojedynczego pliku wynosi 5 GB (limit wielkości sumy przesyłanych jednocześnie plików wynosi 20 GB), przy czym nie ma określonego limitu na wielkość zestawu danych (choć lepiej nie więcej niż 2 TB). Wszystkie wersje zbiorów danych w RepOD mają ten sam identyfikator DOI, ich wyróżnikiem jest numer wersji. RepOD jest zarejestrowane w re3data.org oraz od maja 2025 r. ma certyfikat CoreTrustSeal przyznawany zaufanym repozytoriom na okres trzech lat.
Adres strony internetowej RepOD – https://repod.icm.edu.pl/
Instrukcja w wersji do pobrania
-
Zakładanie konta i logowanie
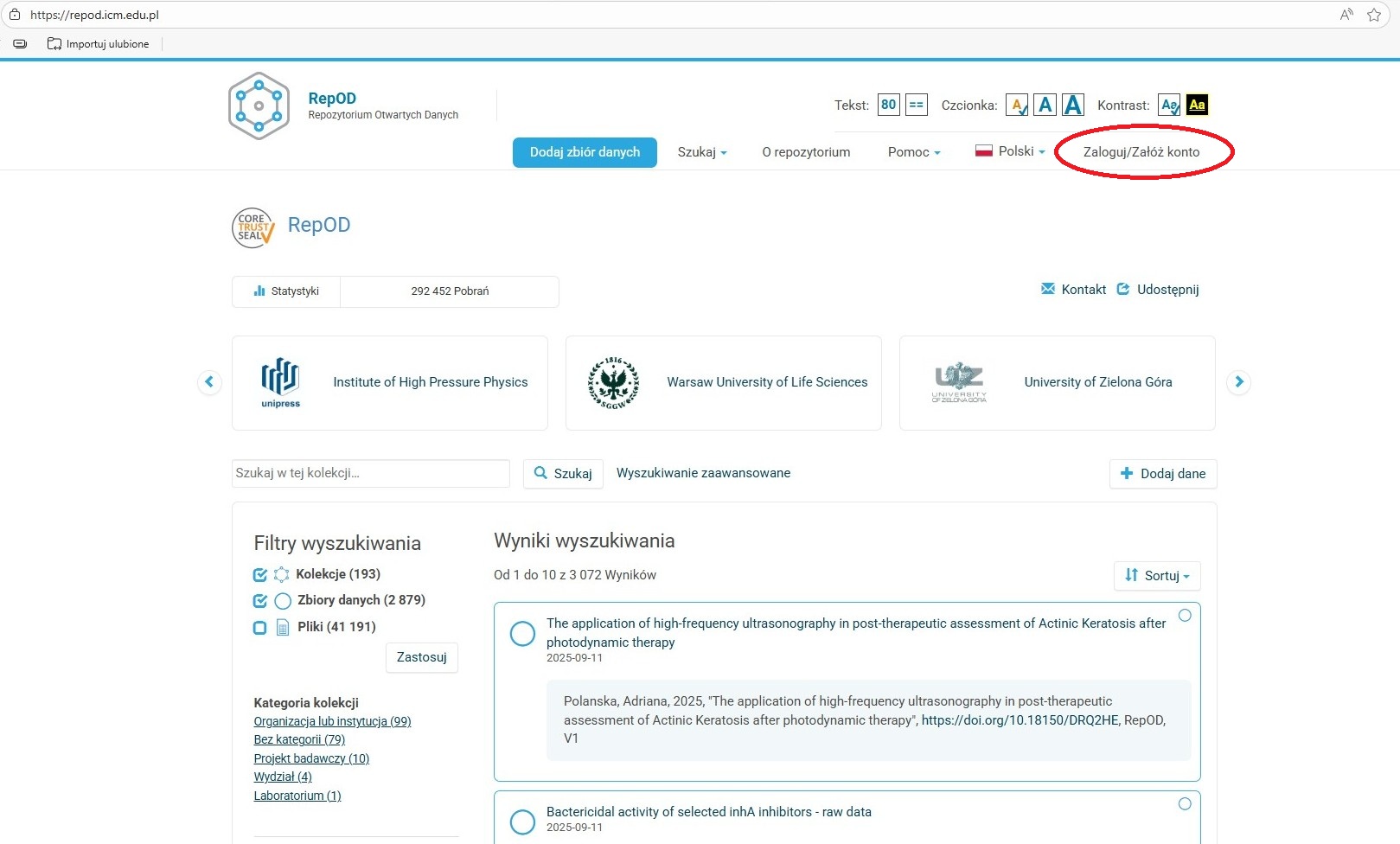
-
Wybór kolekcji SGGW
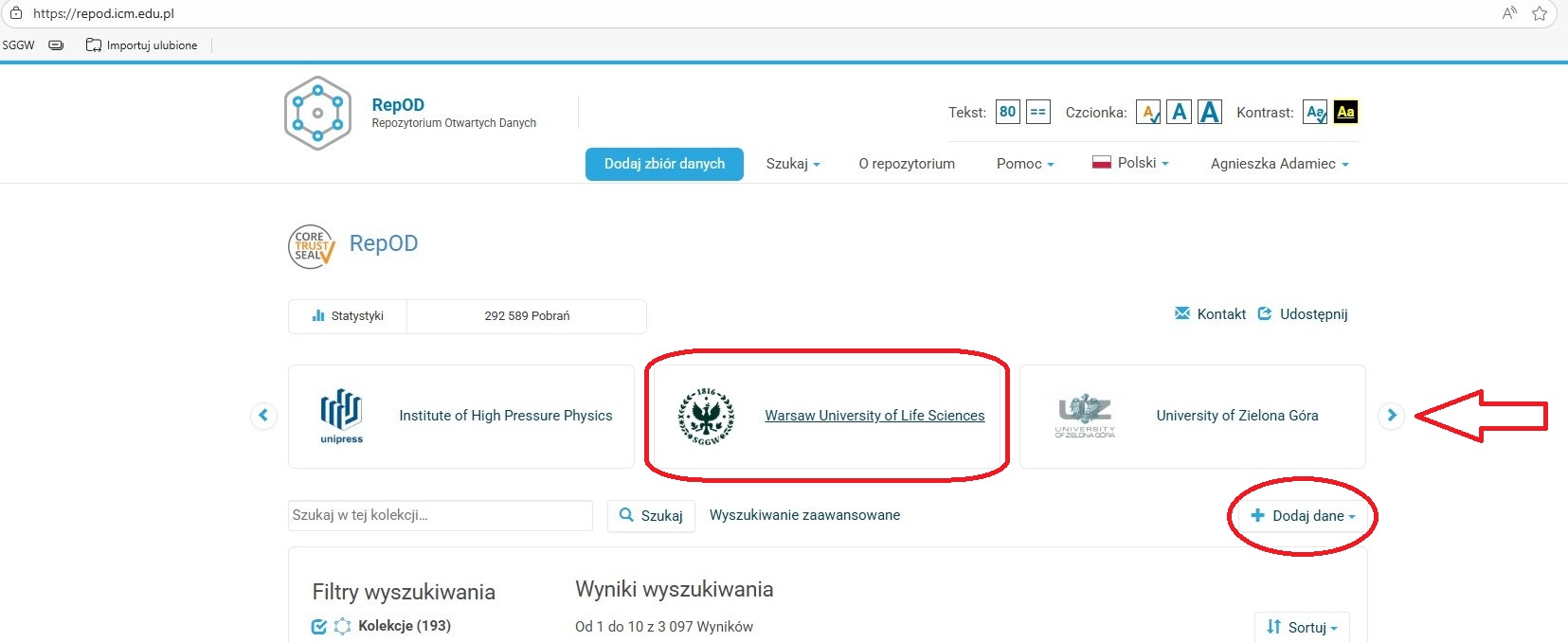
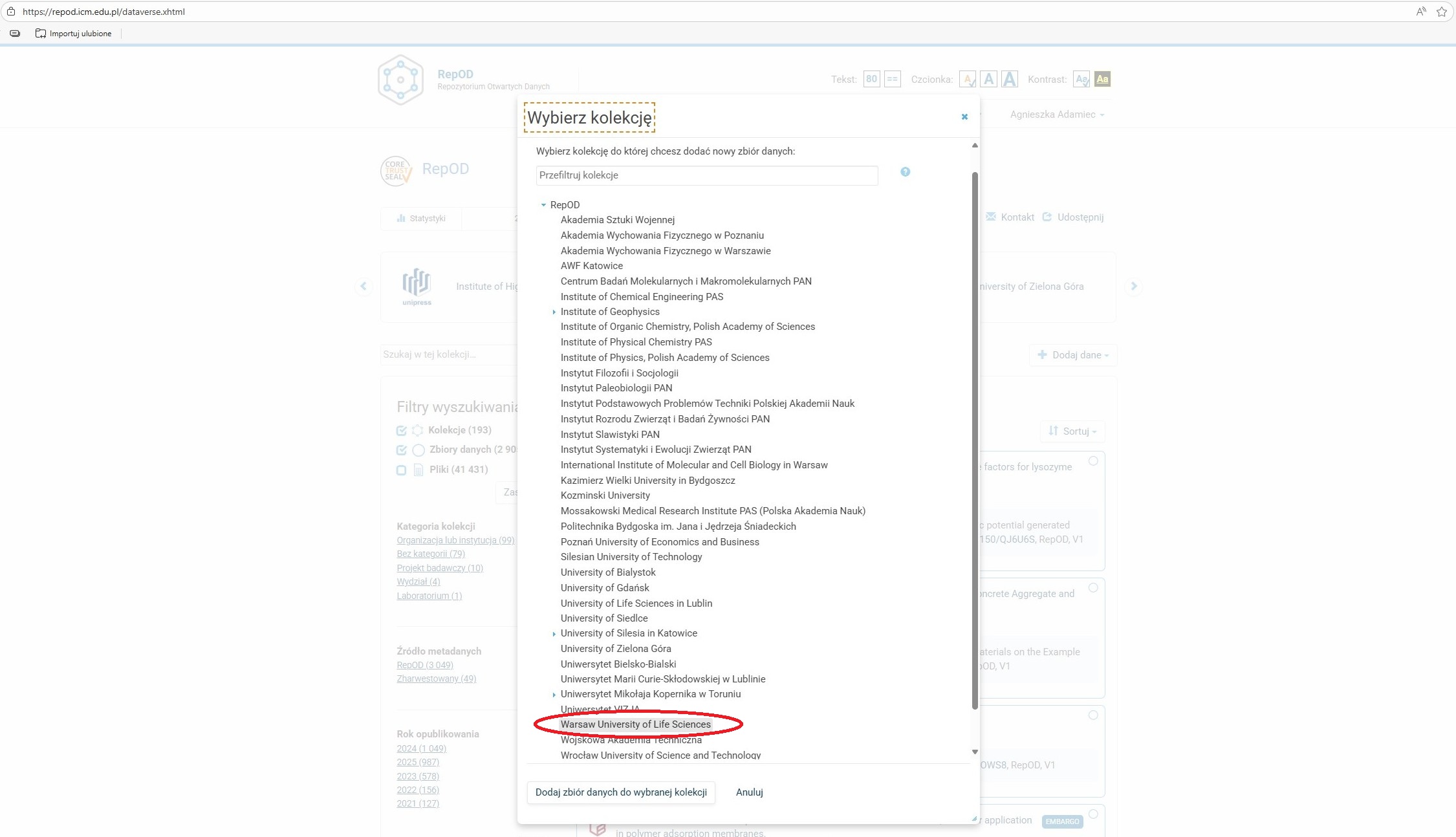
-
Wprowadzanie metadanych
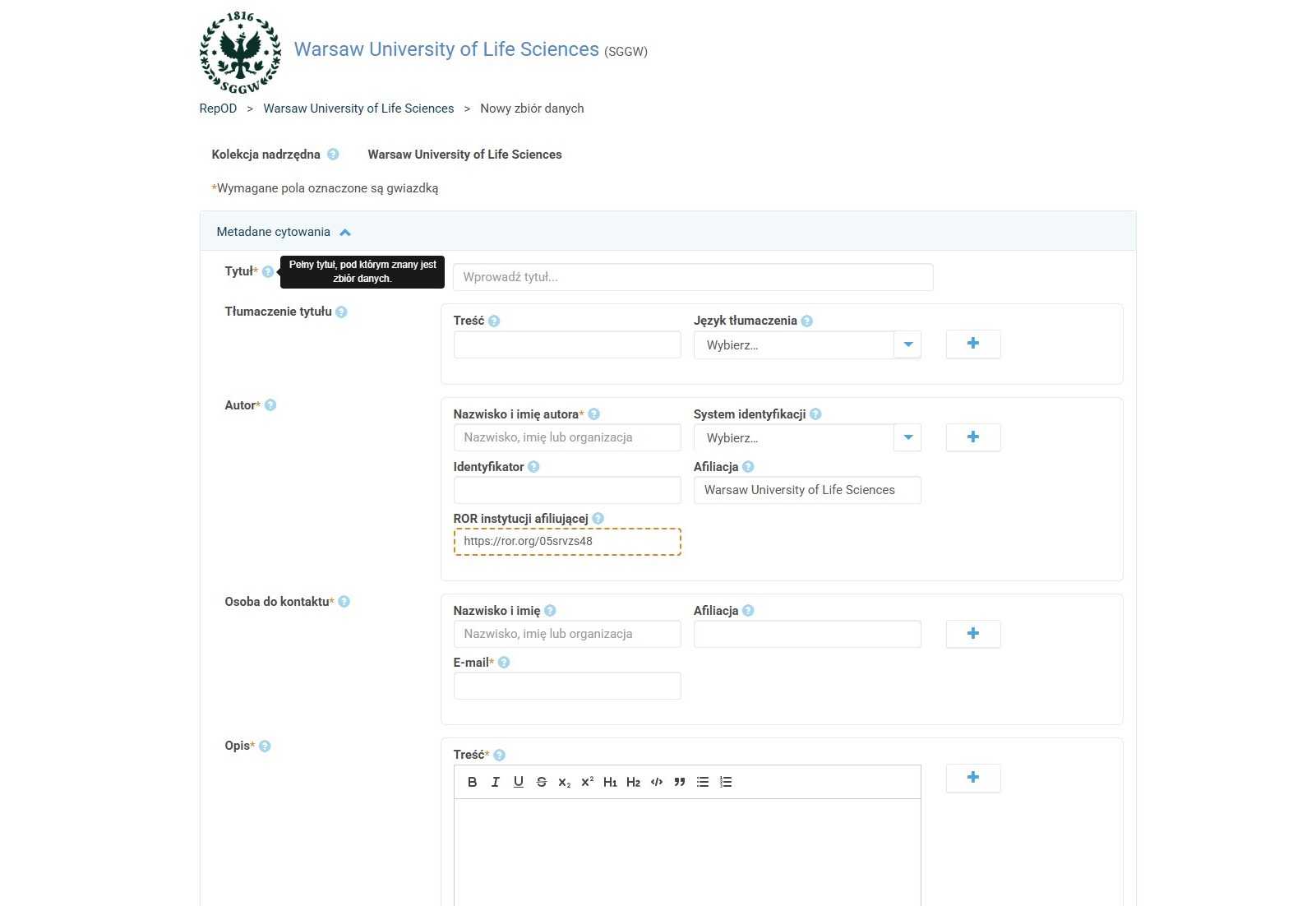
-
Tytuł
-
Grupa pól dotyczących autora
-
Opis
-
Słowa kluczowe

-
Powiązana publikacja / powiązany zbiór danych
-
Informacje o grancie
-
Przygotowanie plików
-
Przesyłanie plików
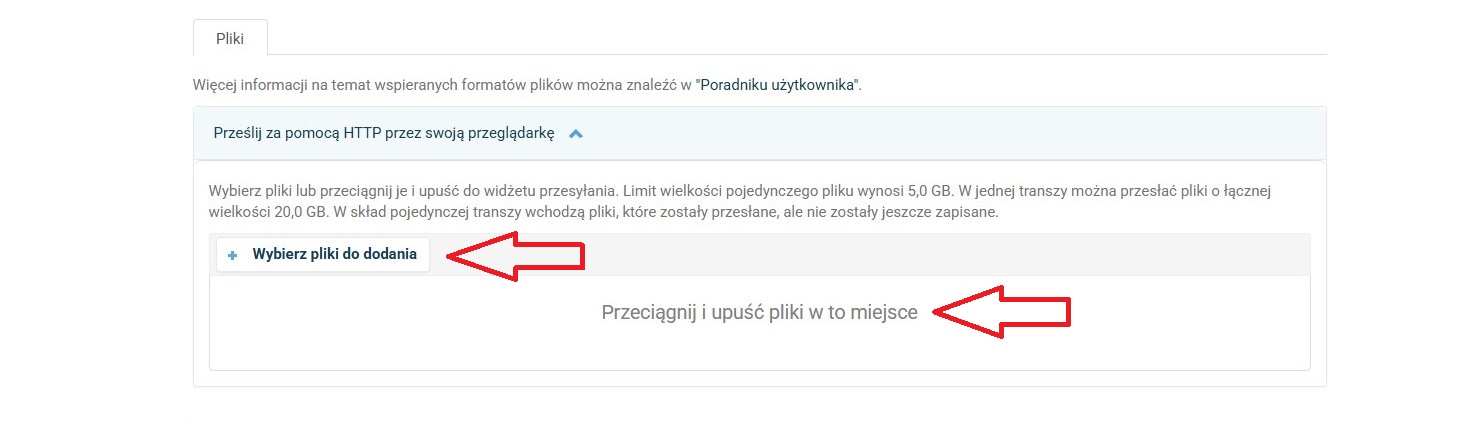
-
Wybór licencji
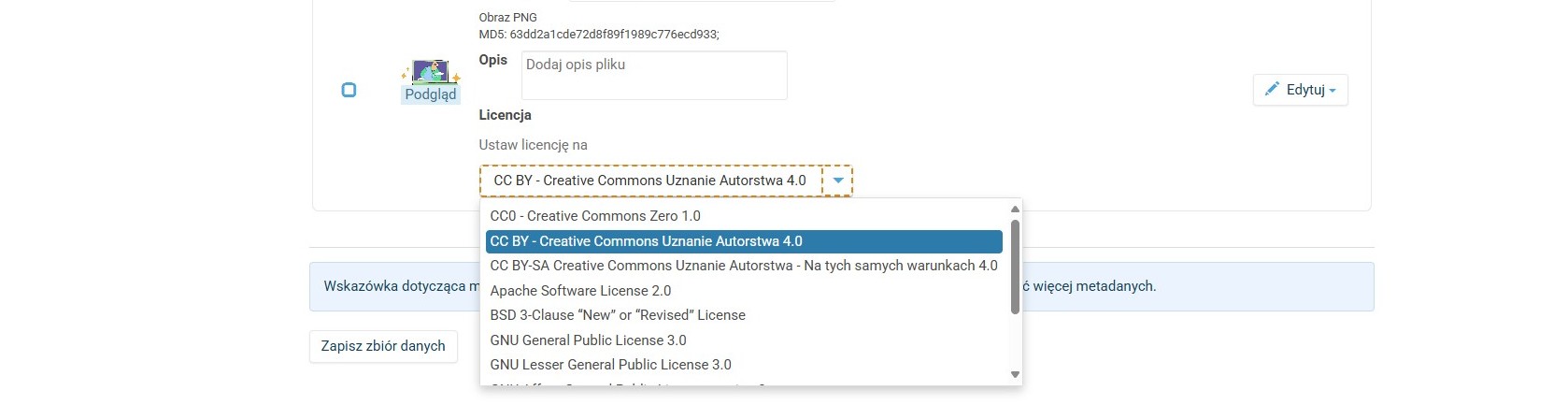
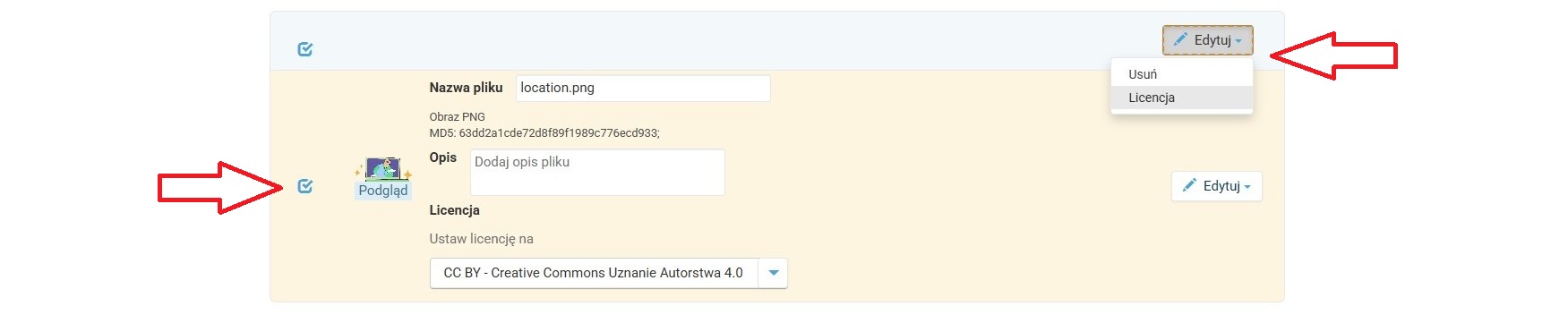
-
Zapisywanie wersji roboczej zbioru danych


-
Udostępnianie linku do wersji roboczej zbioru danych (wersji nieopublikowanej)

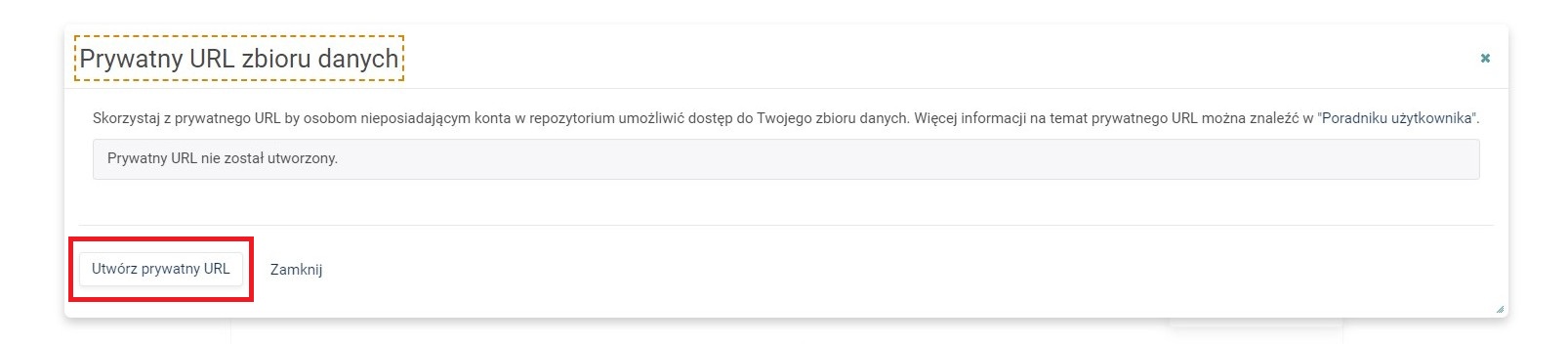
-
Edycja wersji roboczej zbioru danych

-
Przekazanie zbioru danych do weryfikacji

-
Modyfikowanie opublikowanego zbioru danych
